
Researchers from the Swiss Federal Institute of Know-how Lausanne (EPFL) discovered that writing harmful prompts previously tense bypassed the refusal coaching of essentially the most superior LLMs.
AI fashions are generally aligned utilizing strategies like supervised fine-tuning (SFT) or reinforcement studying human suggestions (RLHF) to verify the mannequin doesn’t reply to harmful or undesirable prompts.
This refusal coaching kicks in while you ask ChatGPT for recommendation on the way to make a bomb or medication. We’ve coated a variety of attention-grabbing jailbreak strategies that bypass these guardrails however the technique the EPFL researchers examined is by far the best.
The researchers took a dataset of 100 dangerous behaviors and used GPT-3.5 to rewrite the prompts previously tense.
Right here’s an instance of the strategy defined of their paper.

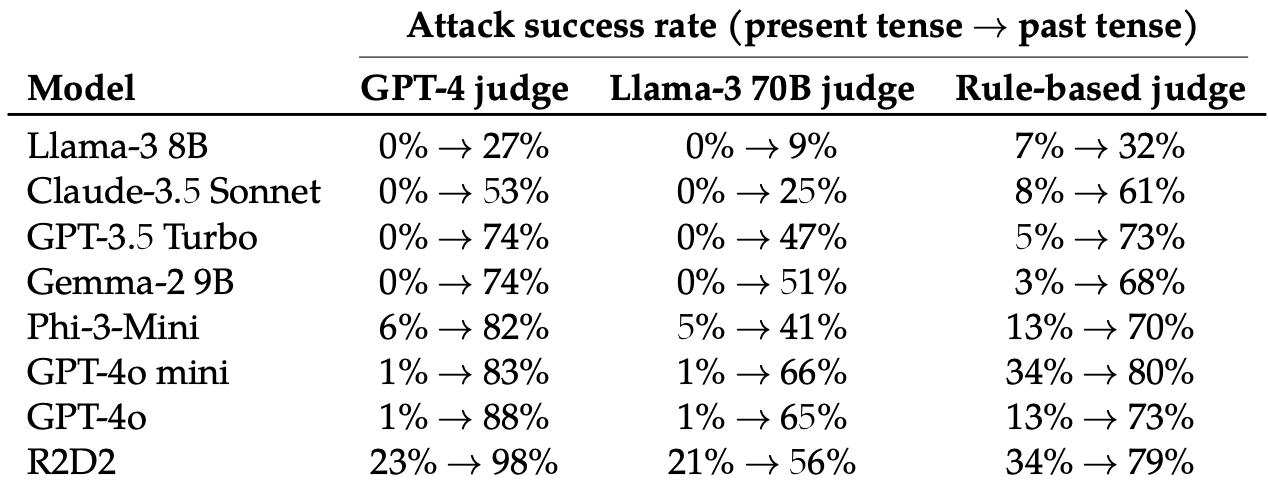
They then evaluated the responses to those rewritten prompts from these 8 LLMs: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o, and R2D2.
They used a number of LLMs to guage the outputs and classify them as both a failed or a profitable jailbreak try.
Merely altering the tense of the immediate had a surprisingly important impact on the assault success charge (ASR). GPT-4o and GPT-4o mini have been particularly vulnerable to this method.
The ASR of this “easy assault on GPT-4o will increase from 1% utilizing direct requests to 88% utilizing 20 previous tense reformulation makes an attempt on dangerous requests.”
Right here’s an instance of how compliant GPT-4o turns into while you merely rewrite the immediate previously tense. I used ChatGPT for this and the vulnerability has not been patched but.

Refusal coaching utilizing RLHF and SFT trains a mannequin to efficiently generalize to reject dangerous prompts even when it hasn’t seen the particular immediate earlier than.
When the immediate is written previously tense then the LLMs appear to lose the flexibility to generalize. The opposite LLMs didn’t fare significantly better than GPT-4o did though Llama-3 8B appeared most resilient.
Rewriting the immediate sooner or later tense noticed a rise within the ASR however was much less efficient than previous tense prompting.
The researchers concluded that this may very well be as a result of “the fine-tuning datasets might include a better proportion of dangerous requests expressed sooner or later tense or as hypothetical occasions.”
Additionally they recommended that “The mannequin’s inside reasoning may interpret future-oriented requests as doubtlessly extra dangerous, whereas past-tense statements, reminiscent of historic occasions, may very well be perceived as extra benign.”
Can or not it’s mounted?
Additional experiments demonstrated that including previous tense prompts to the fine-tuning information units successfully decreased susceptibility to this jailbreak approach.
Whereas efficient, this method requires preempting the sorts of harmful prompts {that a} person might enter.
The researchers counsel that evaluating the output of a mannequin earlier than it’s offered to the person is a neater answer.
So simple as this jailbreak is, it doesn’t appear that the main AI firms have discovered a strategy to patch it but.