
Introduction
Because the launch of GPT fashions by OpenAI, reminiscent of GPT 4o, the panorama of Pure Language Processing has been modified fully and moved to a brand new notion referred to as Generative AI. Giant Language Fashions are on the core of it, which may perceive complicated human queries and generate related solutions to them. The subsequent step to this LLM is the multimodality. That’s the potential to know information apart from textual content. This may embody photos, audio, and movies. Among the multimodels have not too long ago been launched, each open supply and closed sources, just like the Gemini from Google, LlaVa, and GPT 4v. Lately a more recent multi-model has been introduced by OpenAI referred to as the GPT 4o (Omni). On this article, we shall be making a multimodal chatbot with this OpenAI GPT 4o
Studying Targets
- Perceive GPT-4o and its capabilities in textual content, audio, and picture technology
- Learn to create helper capabilities for processing consumer enter (photos and audio) for GPT-4o
- Construct a multimodal chatbot utilizing Chainlit that interacts with GPT-4o
- Implement functionalities for dealing with textual content, picture, and audio inputs within the chatbot
- Acknowledge the advantages of utilizing a multimodal strategy for chatbot interactions
- Discover potential purposes of GPT-4o’s multimodal capabilities
This text was printed as part of the Information Science Blogathon.
What’s GPT 4o?
The not too long ago introduced OpenAI’s GPT-4o marks an enormous leap in AI for its pace, accuracy, and skill to know and generate textual content, audio, and pictures. This “multilingual” mannequin can translate languages, write artistic content material, analyze or generate speech with various tones, and even describe real-world scenes or create photos based mostly in your descriptions. Past its spectacular capabilities, GPT-4o integrates seamlessly with ChatGPT, permitting real-time conversations the place it could actually determine visible data and ask related questions. This potential to work together throughout modalities paves the way in which for a extra pure and intuitive means of interacting with computer systems, doubtlessly aiding visually impaired customers and creating new creative mediums. GPT-4o stands out as a groundbreaking next-gen mannequin that pushes the boundaries of AI
Additionally learn: The Omniscient GPT-4o + ChatGPT is HERE!
Creating the Helper Features
On this part, we’ll start writing the code for the multimodal chatbot. Step one can be to obtain the required libraries that we are going to want for this code to work. To do that, we run the beneath command
pip set up openai chainlitOperating it will set up the OpenAI library. It will allow us to work with the totally different OpenAI fashions, which embody the textual content technology fashions just like the GPT 4o and GPT 3.5, the picture technology fashions just like the DallE-3, and the Speech2Text fashions just like the Whisper.
We set up chainlit for creating the UI. Chainlit library lets us create fast chatbots fully in Python with out writing Javascript, HTML, or CSS. Earlier than starting with the chatbot, we have to create some helper capabilities. The primary one is for photos. We can not instantly present photos of the mannequin. We have to encode them to base64 after which give it. For this, we work with the next code
import base64
def image2base64(image_path):
with open(image_path, "rb") as img:
encoded_string =, base64.b64encode(img.learn())
return encoded_string.decode("utf-8")
- First, we import the base64 library for encoding. Then, we create a operate named image_2_base64() to take an image_path as enter.
- Subsequent, we open the picture with the offered path in read-bytes mode. Then, we name the b64encode() technique from the base64 library, which encodes the picture to base64.
- The encoded information is in bytes, so we have to convert it to the Unicode format the mannequin expects to move this Picture together with the consumer question.
- Therefore, we name the decode() technique, which takes within the base64-encoded bytes and returns a Unicode string by decoding them with UTF-8 encoding.
- Lastly, we return the base64 encoded string, which may be joined with textual content to be despatched to the GPT-4o mannequin
- On a excessive degree, what we do is, we convert the picture to “Base 64 encoded bytes” and “Base 64 encoded bytes” to “Base 64 encoded string”
The multimodal chat even expects audio inputs. So, we even must course of the audio earlier than sending it to the mannequin. For this, we work with the Speech-to-text mannequin from OpenAI. The code for this shall be
from openai import OpenAI
shopper = OpenAI()
def audio_process(audio_path):
audio_file = open(audio_path, "rb")
transcription = shopper.audio.transcriptions.create(
mannequin="whisper-1", file=audio_file
)
return transcription.textual content- We begin by importing the OpenAI class from the OpenAI operate. Ensure that an OpenAI API secret’s current in a .env file
- Subsequent, we instantiate an OpenAI object and retailer this object within the variable shopper
- Now, we create a operate referred to as the audio_process(), which expects an audio path for the enter
- Then we open the file in learn mode and retailer the ensuing bytes within the variable audio_file
- We then name the shopper.audio.transcriptions.create() operate and provides the audio_file to this operate. Together with this, we even inform the mannequin identify we need to work with for speech-to-text conversion. Right here we give it “whisper-1”
- Calling the above operate will move the audio_file contents to that mannequin and the respective transcripts are saved within the transcription variable
- We then lastly return to the textual content half, which is the precise transcription of the audio from this operate
We can not anticipate what kind of message the consumer will ask the mannequin. The consumer could typically simply ship plain textual content, typically could embody a picture, and typically could embody an audio file. So, based mostly on that, we have to alter the message that we are going to ship to the OpenAI mannequin. For this, we are able to write one other operate that may present totally different consumer inputs to the mannequin. The code for this shall be
def append_messages(image_url=None, question=None, audio_transcript=None):
message_list = []
if image_url:
message_list.append({"kind": "image_url", "image_url": {"url": image_url}})
if question and never audio_transcript:
message_list.append({"kind": "textual content", "textual content": question})
if audio_transcript:
message_list.append({"kind": "textual content", "textual content": question + "n" + audio_transcript})
response = shopper.chat.completions.create(
mannequin="gpt-4o",
messages=[{"role": "user", "content": message_list}],
max_tokens=1024,
)
return response.decisions[0]- We create a operate referred to as append_messages(), the place we outline three parameters. One is image_url, the second is the consumer question, and the ultimate one is the audio transcript
- Then, we create an empty message_list variable by assigning an empty checklist
- Subsequent, we verify if an image_url is offered, and whether it is, then we create a dictionary with the important thing “kind” and worth “image_url,” and the opposite secret’s the “image_url” and to this, we move one other dictionary by giving the image_url with which the operate was referred to as. That is the format that OpenAI expects for sending the picture
- Then, we verify if a question is offered and no audio_transcript. Then we simply append one other dictionary to the messag_list with key-value pairs that we see within the code
- Lastly, we verify if an audio_transcript is offered to the operate, and whether it is, then we mix it within the consumer question and append it to the message checklist
- Then we name the shopper.chat.completions.create() operate, the place we move the mannequin, which right here is the GPT-4o, and the message_list that we’ve created earlier and retailer the consequence within the response variable
- We’ve even set the max_tokens to 1024. Aside from these, we are able to even give additional parameters like temperature, top_p and top_k
- Lastly, we retailer to return the response generated by the GPT 4 Omni by returning the response.decisions[0]
With this, we’ve accomplished with creating the helper capabilities. We shall be calling these helper capabilities later to move consumer queries, audio, and picture information and get the responses again
Additionally learn: Right here’s How You Can Use GPT 4o API for Imaginative and prescient, Textual content, Picture & Extra.
Constructing the Chatbot UI
Now, we shall be constructing the UI a part of the Chatbot. This may be constructed very simply with the Chainlit library. The code we’ll write shall be in the identical file the place our helper capabilities are outlined. The code for this shall be
import chainlit as cl
@cl.on_message
async def chat(msg: cl.Message):
photos = [file for file in msg.elements if "image" in file.mime]
audios = [file for file in msg.elements if "audio" in file.mime]
if len(photos) > 0:
base64_image = image2base64(photos[0].path)
image_url = f"information:picture/png;base64,{base64_image}"
elif len(audios) > 0:
textual content = audio_process(audios[0].path)
response_msg = cl.Message(content material="")
if len(photos) == 0 and len(audios) == 0:
response = append_messages(question=msg.content material)
elif len(audios) == 0:
response = append_messages(image_url=image_url, question=msg.content material)
else:
response = append_messages(question=msg.content material, audio_transcript=textual content)
response_msg.content material = response.message.content material
await response_msg.ship()- We begin by importing the chainlit library. Then we create a beautify @cl.on_message(), which tells that the operate beneath it will get run when a consumer varieties in a message
- Chainlit library expects an async operate. Therefore, we outline an async operate referred to as chat, which accepts a variable referred to as cl.Message. Regardless of the consumer varieties in or offers audio or photos, all the pieces is saved within the cl.Message
- msg.parts comprises an inventory of kinds of messages the consumer sends. These may be plain textual content consumer queries or a consumer question with a picture or an audio
- Therefore, we verify if there are some photos or audio information current within the consumer message and retailer them in photos and audio variable
- Now, we verify with an if block, if photos are current, then we convert them to base64 string and retailer them within the image_url variable in a format that the GPT-4o mannequin expects
- We even verify if audio is current, and whether it is, then we course of that audio by calling the audio_process() operate, which returns the audio transcription and is saved within the variable referred to as textual content
- Then we create a message placeholder response_img by giving it an empty message
- Then once more, we verify for some photos or audio. If each should not current, we solely ship the consumer question to the append_message operate, and if even one audio/photos are current, then we even move them to the append_messages operate
- Then, we retailer the consequence from the mannequin within the response variable, and we append it to the placeholder message variable response_msg that we created earlier
- Lastly, we name the response_msg.ship(), which can show the response within the UI
Additionally learn: What Can You Do With GPT-4o? | Demo
The ultimate code shall be
from openai import OpenAI
import base64
import chainlit as cl
shopper = OpenAI()
def append_messages(image_url=None, question=None, audio_transcript=None):
message_list = []
if image_url:
message_list.append({"kind": "image_url", "image_url": {"url": image_url}})
if question and never audio_transcript:
message_list.append({"kind": "textual content", "textual content": question})
if audio_transcript:
message_list.append({"kind": "textual content", "textual content": question + "n" + audio_transcript})
response = shopper.chat.completions.create(
mannequin="gpt-4o",
messages=[{"role": "user", "content": message_list}],
max_tokens=1024,
)
return response.decisions[0]
def image2base64(image_path):
with open(image_path, "rb") as img:
encoded_string = base64.b64encode(img.learn())
return encoded_string.decode("utf-8")
def audio_process(audio_path):
audio_file = open(audio_path, "rb")
transcription = shopper.audio.transcriptions.create(
mannequin="whisper-1", file=audio_file
)
return transcription.textual content
@cl.on_message
async def chat(msg: cl.Message):
photos = [file for file in msg.elements if "image" in file.mime]
audios = [file for file in msg.elements if "audio" in file.mime]
if len(photos) > 0:
base64_image = image2base64(photos[0].path)
image_url = f"information:picture/png;base64,{base64_image}"
elif len(audios) > 0:
textual content = audio_process(audios[0].path)
response_msg = cl.Message(content material="")
if len(photos) == 0 and len(audios) == 0:
response = append_messages(question=msg.content material)
elif len(audios) == 0:
response = append_messages(image_url=image_url, question=msg.content material)
else:
response = append_messages(question=msg.content material, audio_transcript=textual content)
response_msg.content material = response.message.content material
await response_msg.ship()
To run this, kind chainlit run app.py on condition that the code is saved in a file named app.py. After operating this command, the localhost:8000 PORT will change into lively, and we shall be introduced with the beneath picture
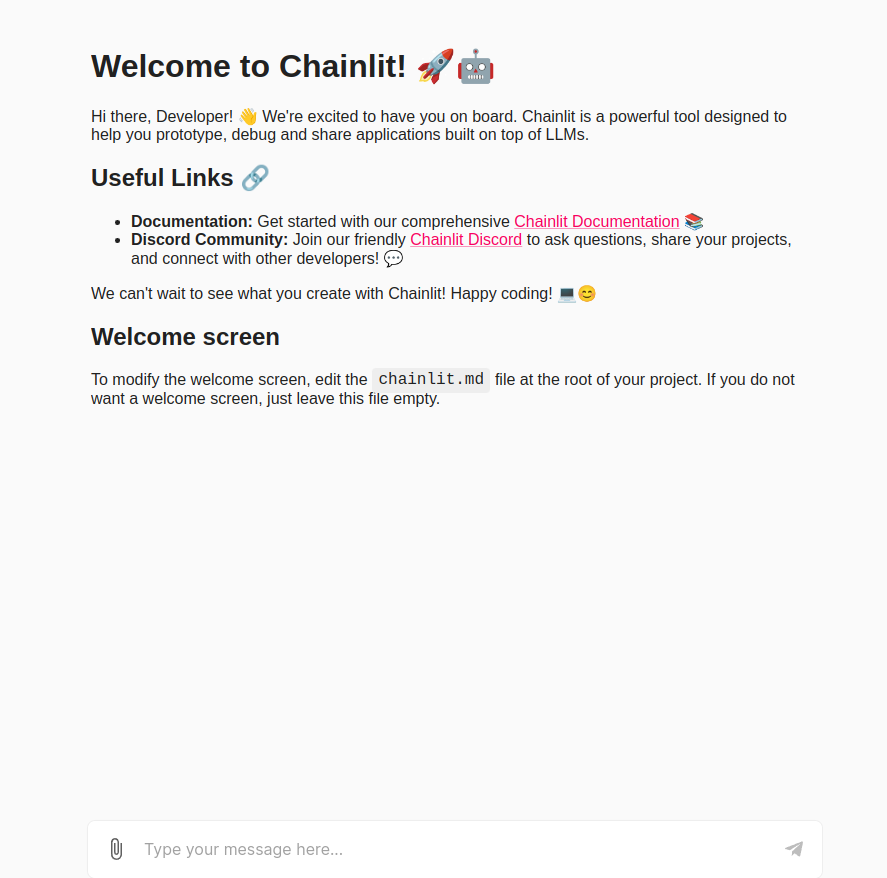
Now allow us to kind in only a regular textual content question and see the output generated
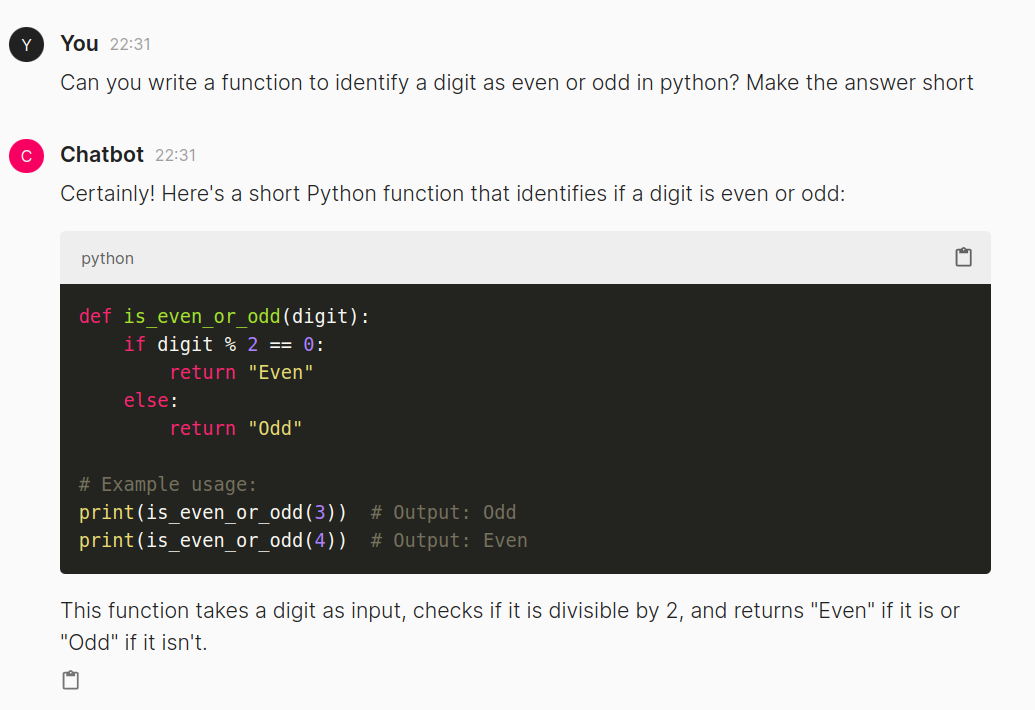
We see that the GPT-4o efficiently generated an output for the consumer question. We even discover that the code is being highlighted right here, and we are able to copy and paste it rapidly. That is all managed by Chainlit, which handles the underlying HTML, CSS, and Javascript. Subsequent, allow us to attempt giving a picture and asking about it the mannequin.
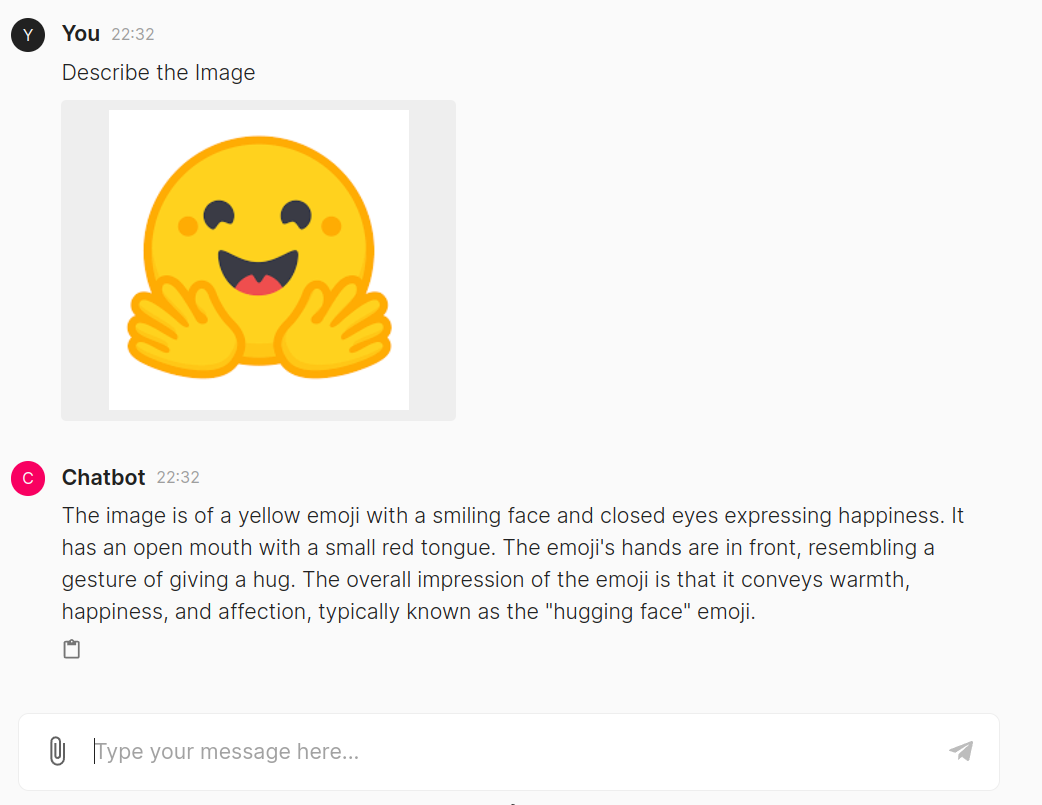
Right here, the mannequin has responded effectively to the picture we uploaded. It recognized that the picture is an emoji and gave details about what it’s and the place it may be used. Now, allow us to move an audio file and check it
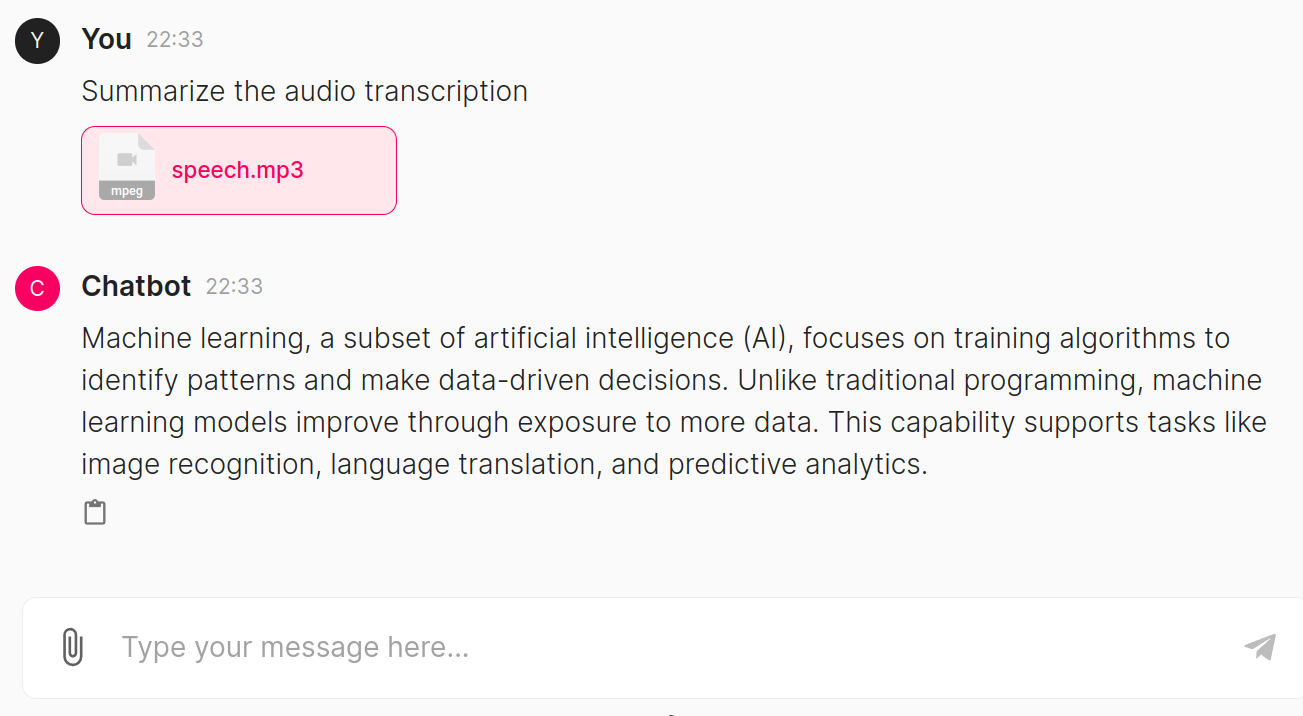
The speech.mp3 audio comprises details about Machine Studying, so we requested the mannequin to summarize its contents. The mannequin generated a abstract that’s related to the content material current within the audio file.
Conclusion
In conclusion, creating a multimodal chatbot utilizing OpenAI’s GPT-4o (Omni) marks an important feat in AI know-how, ushering in a brand new period of interactive experiences. Right here, we’ve explored seamlessly integrating textual content, photos, and audio inputs into conversations with the chatbot, leveraging the capabilities of GPT-4o. This progressive strategy enhances consumer engagement and opens doorways to totally different sensible purposes, from aiding visually impaired customers to creating new creative mediums. By combining the ability of language understanding with multimodal capabilities, GPT-4o exhibits its potential to revolutionize how we work together with AI methods
Key Takeaways
- GPT-4o represents an enormous second in AI, providing textual content, audio, and picture understanding and technology in only a single mannequin
- Integration of multimodal performance into chatbots provides extra pure and intuitive interactions, growing consumer engagement and expertise
- Helper capabilities play an important function in preprocessing inputs, like encoding photos to base64 and transcribing audio information, earlier than feeding them into the mannequin
- The append_messages operate dynamically adjusts enter codecs based mostly on Consumer Queries, thus taking in plain textual content, photos, and audio transcripts
- Chainlit library simplifies the event of chatbot interfaces, dealing with underlying HTML, CSS, and JavaScript, making UI creation straightforward
The media proven on this article should not owned by Analytics Vidhya and is used on the Creator’s discretion.
Continuously Requested Questions
A. GPT-4o is a groundbreaking AI mannequin developed by OpenAI that may perceive and generate textual content, audio, and pictures.
A. GPT-4o units itself aside by integrating textual content, audio, and picture understanding and technology in a single mannequin.
A. GPT-4o can translate languages, create totally different types of artistic content material, analyze or generate speech with totally different tones, and describe real-world scenes or create photos based mostly on descriptions.
A. The multimodal chatbot works with GPT-4o’s capabilities to know and reply to consumer queries, together with textual content, photos, or audio inputs.
A. The mandatory libraries for constructing the chatbot embody OpenAI for accessing GPT-4o, Chainlit for creating the UI, and base64 for encoding photos.
A. Chainlit simplifies the event of chatbot interfaces by managing underlying HTML, CSS, and JavaScript, making UI creation fast and environment friendly.